Playing Snake with RL
(based on this project)
Note: I highly recommend running this on a local setup, as Colab doesn’t have good support for pygame.
Objective
Train an RL agent to improve Snake gameplay using reward-driven learning.
Prerequisites
- Comfort with Python OOP and control flow
- Basic understanding of tensors and neural network training
Setup
- Prefer local environment (pygame support).
- Install dependencies listed below.
Tasks
- Implement environment and agent components.
- Train the model and track score progression.
- Interpret exploration-to-exploitation behavior during training.
Dependencies
We need a few dependencies for this project, which you can install using pip or anaconda:
- numpy
- matplotlib
- pytorch
- pygame
Setting up the game
Before we can do any RL, let’s setup our game environment. We’ll use pygame for the game visualization.
imports
import pygame
import random
from enum import Enum
from collections import namedtuple
import numpy as np
initializing pygame (visualization)
pygame.init()
# font = pygame.font.Font('arial.ttf', 25)
font = pygame.font.SysFont('arial', 25)
class Direction(Enum):
RIGHT = 1
LEFT = 2
UP = 3
DOWN = 4
Point = namedtuple('Point', 'x, y')
# rgb colors
WHITE = (255, 255, 255)
RED = (200,0,0)
BLUE1 = (0, 0, 255)
BLUE2 = (0, 100, 255)
BLACK = (0,0,0)
BLOCK_SIZE = 20
SPEED = 40
snake game functions
class SnakeGameAI:
def __init__(self, w=640, h=480):
self.w = w
self.h = h
# init display
self.display = pygame.display.set_mode((self.w, self.h))
pygame.display.set_caption('Snake')
self.clock = pygame.time.Clock()
self.reset()
def reset(self):
# init game state
self.direction = Direction.RIGHT
self.head = Point(self.w/2, self.h/2)
self.snake = [self.head,
Point(self.head.x-BLOCK_SIZE, self.head.y),
Point(self.head.x-(2*BLOCK_SIZE), self.head.y)]
self.score = 0
self.food = None
self._place_food()
self.frame_iteration = 0
def _place_food(self):
x = random.randint(0, (self.w-BLOCK_SIZE )//BLOCK_SIZE )*BLOCK_SIZE
y = random.randint(0, (self.h-BLOCK_SIZE )//BLOCK_SIZE )*BLOCK_SIZE
self.food = Point(x, y)
if self.food in self.snake:
self._place_food()
def play_step(self, action):
self.frame_iteration += 1
# 1. collect user input
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
# 2. move
self._move(action) # update the head
self.snake.insert(0, self.head)
# 3. check if game over
reward = 0
game_over = False
if self.is_collision() or self.frame_iteration > 100*len(self.snake):
game_over = True
reward = -10
return reward, game_over, self.score
# 4. place new food or just move
if self.head == self.food:
self.score += 1
reward = 10
self._place_food()
else:
self.snake.pop()
# 5. update ui and clock
self._update_ui()
self.clock.tick(SPEED)
# 6. return game over and score
return reward, game_over, self.score
def is_collision(self, pt=None):
if pt is None:
pt = self.head
# hits boundary
if pt.x > self.w - BLOCK_SIZE or pt.x < 0 or pt.y > self.h - BLOCK_SIZE or pt.y < 0:
return True
# hits itself
if pt in self.snake[1:]:
return True
return False
def _update_ui(self):
self.display.fill(BLACK)
for pt in self.snake:
pygame.draw.rect(self.display, BLUE1, pygame.Rect(pt.x, pt.y, BLOCK_SIZE, BLOCK_SIZE))
pygame.draw.rect(self.display, BLUE2, pygame.Rect(pt.x+4, pt.y+4, 12, 12))
pygame.draw.rect(self.display, RED, pygame.Rect(self.food.x, self.food.y, BLOCK_SIZE, BLOCK_SIZE))
text = font.render("Score: " + str(self.score), True, WHITE)
self.display.blit(text, [0, 0])
pygame.display.flip()
def _move(self, action):
# [straight, right, left]
clock_wise = [Direction.RIGHT, Direction.DOWN, Direction.LEFT, Direction.UP]
idx = clock_wise.index(self.direction)
if np.array_equal(action, [1, 0, 0]):
new_dir = clock_wise[idx] # no change
elif np.array_equal(action, [0, 1, 0]):
next_idx = (idx + 1) % 4
new_dir = clock_wise[next_idx] # right turn r -> d -> l -> u
else: # [0, 0, 1]
next_idx = (idx - 1) % 4
new_dir = clock_wise[next_idx] # left turn r -> u -> l -> d
self.direction = new_dir
x = self.head.x
y = self.head.y
if self.direction == Direction.RIGHT:
x += BLOCK_SIZE
elif self.direction == Direction.LEFT:
x -= BLOCK_SIZE
elif self.direction == Direction.DOWN:
y += BLOCK_SIZE
elif self.direction == Direction.UP:
y -= BLOCK_SIZE
self.head = Point(x, y)
Agent
Now that we’ve setup our game, lets work on our agent.
imports and variables
import torch
import random
import numpy as np
from collections import deque
MAX_MEMORY = 100_000
BATCH_SIZE = 1000
LR = 0.001
Agent Class
Here, we define the agent class that we can use in our RL model. We define our state with snake positions, directions, danger, and food positions. When choosing a move, we choose bewteen a random move and a predicted move, depending on our epsilon value.
class Agent:
def __init__(self):
self.n_games = 0
self.epsilon = 0 # randomness
self.gamma = 0.9 # discount rate
self.memory = deque(maxlen=MAX_MEMORY) # popleft()
self.model = Linear_QNet(11, 256, 3)
self.trainer = QTrainer(self.model, lr=LR, gamma=self.gamma)
def get_state(self, game):
head = game.snake[0]
point_l = Point(head.x - 20, head.y)
point_r = Point(head.x + 20, head.y)
point_u = Point(head.x, head.y - 20)
point_d = Point(head.x, head.y + 20)
dir_l = game.direction == Direction.LEFT
dir_r = game.direction == Direction.RIGHT
dir_u = game.direction == Direction.UP
dir_d = game.direction == Direction.DOWN
state = [
# Danger straight
(dir_r and game.is_collision(point_r)) or
(dir_l and game.is_collision(point_l)) or
(dir_u and game.is_collision(point_u)) or
(dir_d and game.is_collision(point_d)),
# Danger right
(dir_u and game.is_collision(point_r)) or
(dir_d and game.is_collision(point_l)) or
(dir_l and game.is_collision(point_u)) or
(dir_r and game.is_collision(point_d)),
# Danger left
(dir_d and game.is_collision(point_r)) or
(dir_u and game.is_collision(point_l)) or
(dir_r and game.is_collision(point_u)) or
(dir_l and game.is_collision(point_d)),
# Move direction
dir_l,
dir_r,
dir_u,
dir_d,
# Food location
game.food.x < game.head.x, # food left
game.food.x > game.head.x, # food right
game.food.y < game.head.y, # food up
game.food.y > game.head.y # food down
]
return np.array(state, dtype=int)
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done)) # popleft if MAX_MEMORY is reached
def train_long_memory(self):
if len(self.memory) > BATCH_SIZE:
mini_sample = random.sample(self.memory, BATCH_SIZE) # list of tuples
else:
mini_sample = self.memory
states, actions, rewards, next_states, dones = zip(*mini_sample)
self.trainer.train_step(states, actions, rewards, next_states, dones)
#for state, action, reward, nexrt_state, done in mini_sample:
# self.trainer.train_step(state, action, reward, next_state, done)
def train_short_memory(self, state, action, reward, next_state, done):
self.trainer.train_step(state, action, reward, next_state, done)
def get_action(self, state):
# random moves: tradeoff exploration / exploitation
self.epsilon = 80 - self.n_games
final_move = [0,0,0]
if random.randint(0, 200) < self.epsilon:
move = random.randint(0, 2)
final_move[move] = 1
else:
state0 = torch.tensor(state, dtype=torch.float)
prediction = self.model(state0)
move = torch.argmax(prediction).item()
final_move[move] = 1
return final_move
Training Loop This defines how the training loop works. We get the old state, get an action, and evaluate that action. Then, we save this to the memory. If the game is over, we and reset the board and update the plot of scores with the previous run.
def train():
plot_scores = []
plot_mean_scores = []
total_score = 0
record = 0
agent = Agent()
game = SnakeGameAI()
while True:
# get old state
state_old = agent.get_state(game)
# get move
final_move = agent.get_action(state_old)
# perform move and get new state
reward, done, score = game.play_step(final_move)
state_new = agent.get_state(game)
# train short memory
agent.train_short_memory(state_old, final_move, reward, state_new, done)
# remember
agent.remember(state_old, final_move, reward, state_new, done)
if done:
# train long memory, plot result
game.reset()
agent.n_games += 1
agent.train_long_memory()
if score > record:
record = score
agent.model.save()
print('Game', agent.n_games, 'Score', score, 'Record:', record)
plot_scores.append(score)
total_score += score
mean_score = total_score / agent.n_games
plot_mean_scores.append(mean_score)
plot(plot_scores, plot_mean_scores)
Prediction Model
This prediction model implements a deep Q-learning framework, which approximates our Q-function, or the expected cumulative reward for a given action in a given state.
imports
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import os
Linear Q Network This defines our linear Q neural network. It has 3 layers (input, hidden, output).
class Linear_QNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
def save(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.makedirs(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
Q Trainer Class This class helps us train our Q Network.
class QTrainer:
def __init__(self, model, lr, gamma):
self.lr = lr
self.gamma = gamma
self.model = model
self.optimizer = optim.Adam(model.parameters(), lr=self.lr)
self.criterion = nn.MSELoss()
def train_step(self, state, action, reward, next_state, done):
state = torch.tensor(state, dtype=torch.float)
next_state = torch.tensor(next_state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.long)
reward = torch.tensor(reward, dtype=torch.float)
# (n, x)
if len(state.shape) == 1:
# (1, x)
state = torch.unsqueeze(state, 0)
next_state = torch.unsqueeze(next_state, 0)
action = torch.unsqueeze(action, 0)
reward = torch.unsqueeze(reward, 0)
done = (done, )
# 1: predicted Q values with current state
pred = self.model(state)
target = pred.clone()
for idx in range(len(done)):
Q_new = reward[idx]
if not done[idx]:
Q_new = reward[idx] + self.gamma * torch.max(self.model(next_state[idx]))
target[idx][torch.argmax(action[idx]).item()] = Q_new
# 2: Q_new = r + y * max(next_predicted Q value) -> only do this if not done
# pred.clone()
# preds[argmax(action)] = Q_new
self.optimizer.zero_grad()
loss = self.criterion(target, pred)
loss.backward()
self.optimizer.step()
Visualization
The last thing to do is define our visualization tools for when our RL script is running.
imports
import matplotlib.pyplot as plt
from IPython import display
plt.ion()
Plot Function
def plot(scores, mean_scores):
display.clear_output(wait=True)
display.display(plt.gcf())
plt.clf()
plt.title('Training...')
plt.xlabel('Number of Games')
plt.ylabel('Score')
plt.plot(scores)
plt.plot(mean_scores)
plt.ylim(ymin=0)
plt.text(len(scores)-1, scores[-1], str(scores[-1]))
plt.text(len(mean_scores)-1, mean_scores[-1], str(mean_scores[-1]))
plt.show(block=False)
plt.pause(.1)
Running the Code
Now that we have all of this defined, all we have to do is run it!
train()
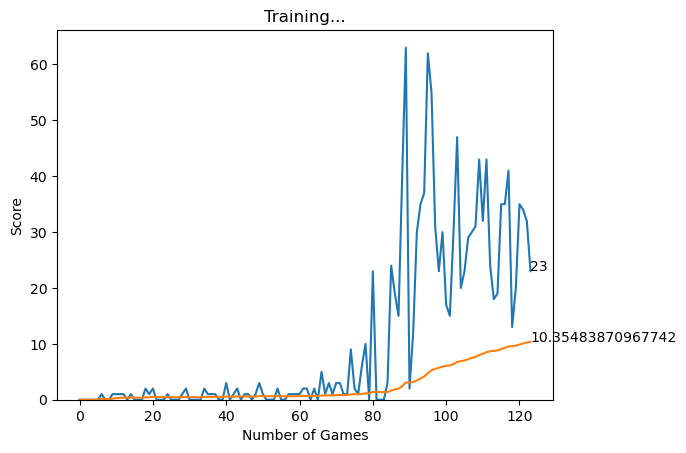
This will start training the RL model. For the first few epochs, the behavior will seem very random (it is!). However, after a bit, you will start to see the RL network figuring out some game properties. After letting it run for a few minutes, the agent easily achieves a score of 20+.
Validation
- Training loop runs for multiple games without runtime errors.
- Score graph trends upward over time (with expected variance).
- Agent behavior qualitatively improves from random to strategic.
Extensions
- Try different epsilon decay schedules and compare learning speed.
- Modify reward shaping and observe policy changes.
- Save and reload model checkpoints for reproducible runs.
Deliverable
- Runnable training script/notebook.
- Score plot image and a short analysis of training behavior.
- Notes on one hyperparameter experiment and outcome.